Поскольку вычисления на кластерах и суперкомпьютерах в HEP сделались
обыденностью, а разработчики научного софта как правило не слишком много
внимания уделяют техникам логирования (и, если и способны различать stderr и
stdout нередко слабо себе представляют, зачем здесь что-то ещё выдумывать),
то анализ беспорядочных логов становится большой проблемой, которую, всё же,
соблазнительно было бы решить средствами ELK.
В этой заметке я рассмотрю пример адаптации ELK-стэка к задаче слежения за логами в одной (весьма типичной) экосистеме самодельного софта, которая представляет собой наследие двадцатилетней работы одной сравнительно крупной коллаборации --- COMPASS (1998-2021, CERN).
Источниками логов в моём случае являются преимущественно процессы двух
программных пакетов: CORAL, осуществляющего первичную реконструкцию событий,
включая применение калибровок и трекинг, и PHAST, средвами которого
производится физический анализ.
Нужно сказать, что функции CORAL'а как пакета достаточно обширны: он не
только производит многоуровневые преобразования сырых экспериментальных данных,
но и осуществляет некоторые инструментальные процедуры вроде геометрического
выравнивания или извлечения калибровочной информации. Десятки исполняемых
файлов внутри него и непрозрачная архитектура вкупе с огромным techical debt
делают совершенно невозможным рефакторинг системы логирования, не говоря уже об
очевидных политических проблемах, которые возникнут у меня, возьмись я за
подобное мероприятие.
Процессы исполняются на кластерах HTCondor или IBM LSF. Принимая во внимания обширные подготовительные процедуры для запуска этих процессов, я довольно быстро отказался от на первый взгляд разумной идеи адаптировать под это дело Luigi или Airflow, и за пару месяцев реализовал собственный набор инструментов, худо-бедно решающий проблему параметризации процессов на кластере.
Столкновение эпох
Проблема в формате логов. Это гремучая смесь из конвенций принятых в
коллаборации в разные годы, отдельных plain printf()'ов печатающих куда
попало случайные мысли разработчиков, критические ошибки из фортрановых
процедур и plain ASCII-таблицы и декорации с псевдографикой. На первый взгляд
безнадёжное дело -- попытаться автоматизировать разбор этих логов, однако
посмотрим, что получится, если воспользоваться современными средствами. Это
своего рода схватка между бешенной энтропией полупрофессионального
программирования двадцатилетней зрелости и легкомысленным порядком хипстерских
технологий последних лет. Типичный кусок лога:
TSetup::Init() ==> INFO: dead zone in detector GM11Y1 will be considered as active
TSetup::Init() ==> INFO: dead zone in detector GM11X1 will be considered as active
-----------------------------------------
CsRwRecons:: RICH Wall reconstruction is OFF!!
CsRwChargeRecons:: RICH Wall charge reconstruction is OFF!!
main - INFO: ================================
main - INFO: = Magnets are asumed to be on
main - INFO: = RequireCop is on
main - INFO: = Chi2Cut: 30
main - INFO: ================================
CsRwRecons:: RICH Wall reconstruction is OFF!!
+--------------------------------------------------------------------------+
1ST EVENT DOWNLOAD started (Sat, 17/Nov/2018 22:41:51 (GMT))
+--------------------------------------------------------------------------+
Time since the Epoch : 1542494511.9713 s
CPU Time (user) : 12.9640 s
CPU Time (sys) : 3.5615 s
+--------------------------------------------------------------------------+
Data stream "cdr11021-285657.raw"
+--------------------------------------------------------------------------+
1ST EVENT DOWNLOAD ended (Sat, 17/Nov/2018 22:41:51 (GMT))
+--------------------------------------------------------------------------+
Time since the Epoch : 1542494511.9714 s, Difference: 0.0001 s
CPU Time (user) : 12.9640 s, Difference: 0.0000 s
CPU Time (sys) : 3.5615 s, Difference: 0.0000 s
+--------------------------------------------------------------------------+
Chip::ReadMaps(): reading files from the directory "/afs/cern.ch/compass/detector/maps/2018.xml/"
Chip::ReadMaps(): Failed to load the map "ChipTDC" from the file /afs/cern.ch/compass/detector/maps/2018.xml//CEDAR.xml
tail0
100 91 80 68 58 49 42 35 31 26 23 19 17 15 13 12 11 10 9 8 7 6 5 5 5 4 4 4 4 3 3 3
tail1
100 93 81 70 60 52 45 40 34 31 27 24 22 19 17 16 14 13 12 11 10 10 9 8 8 6 6 6 6 6 5 5
reading calibration
CsCalorimeter::readCalibration EC01P1__
CsCalorimeter::readCalibration try to read _CALIB
CsCalorimeter::readCalibration try to read _TimeCALIB
CsCalorimeter::readCalibration try to read _TimeCorr
CsCalorimeter::readCalibration EC02P1__
CsCalorimeter::readCalibration try to read _CALIB
CsCalorimeter::readCalibration try to read _TimeCALIB
CsCalorimeter::readCalibration try to read _TimeCorr
Calorimeter::UpdateFrontEndDependentSettings EC02P1__
CALIB ready ? 2972
options.delta_spars_mode_ = 10cf[0]= mean=2.857e-02 sigma=1.828e-02 N=mom0=1.000e+00
Event: 66 (37)
Event: 67 (37)
NOTA BENE, Sat, 17/Nov/2018 20:10:07.991031 (GMT), CsField.cc, 396: SM2: NMR(=1.86096) / map(=-1.91229) => Rescaling=-0.97316 while detectors.dat scale =-1.00000
С одной стороны, я не ставлю себе задачу структурировать то что не имеет
структуры изначально (как и зачем, например, интерпретировать строку, которая
содержит числовую последовательность). Будет здорово, если я
смогу вытаскивать из этих логов хоть какую-то семантику. С другой стороны, я
не из тех кто ищет лёгких путей (самоирония), так что возьмусь-ка, без
всякого предварительного опыта с ELK-стэком писать свой модуль для filebeat.
В этом мне сильно поможет демонстрационное видео
и гайд
от разработчиков.
Dashboards нас пока не интересуют (к тому же, судя по всему, у Kibana есть какой-то графический composer для них). Что меня (да и, наверное, всякого рукодельника) заинтересует прежде всего, так это отладка Grok patterns на живых логах. Онлайн-средства 1, 2 позволяют, в принципе, делать по одному паттерну за раз, но это не позволяет охватить общую картину и сделать какой-то вывод о применимости ELK для конкретного формата логов (или, в моём случае, антиформата, да).
Развёртка ELK в docker
Ну, страничка elk-docker в принципе всё достаточно сжато описывает:
# sysctl -w vm.max_map_count=262144
$ docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -it --name elk sebp/elk
Гайд рекомендует для отладки pipeline'а "simulate pipeline API",
для чего в принципе достаточно было бы наверное и обычным cURL'ом отправлять
запросы, но у Kibana есть плагин "Console".
После того как docker сделал все свои дела, на порту 5601 появляется
веб-интерфейс Kibana. "Console" доступна на вкладке "Dev Tools".
Хотя запуск ELK в Docker и оставляет вам воспроизводимое окружение, которое в любой момент можно сбросить к исходному состоянию, полезно знать следующий сниппет для REST-коммуникации с БД, полностью сбрасывающий индекс elasticsearch:
$ curl -X DELETE 'http://localhost:9200/_all'
Как видите, никаких специальных полномочий для такой операции не требуется, так что рекомендуется принять известные меры безопасности для изолирования своего контейнера.
Прототипирование модуля filebeat
Итак, по ходу видео и гайда делается ясно, что у разработчиков есть какой-то "официальный" git-репозиторий, в котором они держат модули, и прямым текстом декларируется, что они одобряют использование репозитория для кастомизации.
$ git clone https://github.com/elastic/beats.git
$ cd beats/filebeat
$ make create-module MODULE=coral
scripts/generator/module/main.go:26:2: cannot find package "github.com/elastic/beats/filebeat/scripts/generator" in any of:
/usr/lib/golang/src/github.com/elastic/beats/filebeat/scripts/generator (from $GOROOT)
/home/crank/go/src/github.com/elastic/beats/filebeat/scripts/generator (from $GOPATH)
make: *** [Makefile:50: create-module] Ошибка 1
Какая-то go-специфичная ошибка (у меня, к сожалению, нет опыта в этом языке): видимо у go есть свой package manager или что-то вроде того. Ну, понятно:
$ GOPATH=~/go go get github.com/elastic/beats/filebeat/scripts/generator
$ make create-module MODULE=coral
New module was generated, now you can start creating filesets by create-fileset command.
Получившийся скелет модуля:
$ tree module/coral/
module/coral/
├── _meta
│ ├── config.yml
│ ├── docs.asciidoc
│ ├── fields.yml
│ └── kibana
│ └── 6
└── module.yml
3 directories, 4 files
Гайд на мой взгляд слишком концентрируется на частностях, в то время как видео содержит несколько полезных команд, позволяющих, в принципе, применять сырой модуль в качестве демонстрационного стенда (fixture), однако из этих материалов остаётся неясным, что необходимо сделать предварительно. Мой модуль от прочих отличается главным образом тем что в нём нет dashboards (пока?):
$ find module -name docs.asciidoc -exec grep -H ":has-dashboards: false" {} \;
module/elasticsearch/_meta/docs.asciidoc::has-dashboards: false
module/kibana/_meta/docs.asciidoc::has-dashboards: false
Заглянем, как сделан модуль Kibana (да, xzibit.jpg):
$ vim -O module/kibana/_meta/docs.asciidoc module/coral/_meta/docs.asciidoc
Остальные файлы (_meta/*, module.yml) не содержат пока ничего волнующего,
разве что в module.yml рекомендуют записать title в верхнем регистре.
Следующий шаг -- Creating new fileset:
Fileset -- это классификатор типа логов который должен создаваться "for each
type of log that the service creates". Было бы здорово разделить дампы
stdout/stderr к примеру, но это невозможно, потому что в самом софте мало
кто придерживался конвенции разделения потоков.
$ make create-fileset MODULE=coral FILESET=log
New fileset was generated, please check that module.yml file have proper fileset
dashboard settings. After setting up Grok pattern in pipeline.json, please
generate fields.yml
$ tree module/coral/
module/coral/
├── log
│ ├── config
│ │ └── log.yml
│ ├── ingest
│ │ └── pipeline.json
│ ├── manifest.yml
│ ├── _meta
│ └── test
├── _meta
│ ├── config.yml
│ ├── docs.asciidoc
│ ├── fields.yml
│ └── kibana
│ └── 6
└── module.yml
Важный момент -- в содержимом файла manifest.yml можно указать конвенции для
путей, куда ваша сборка пишет логи. У меня есть такие конвенции, однако они
оказались слишком сложны, чтобы на текущем этапе формулировать их в
декларативном виде. Главное пока -- эти конвенции опираются на параметры
которые можно сообщать filebeat снаружи в виде {{.variableName}}, что будет
затем чрезвычайно удобным механизмом для определения целевых логов.
Содержимое module/coral/log/config/log.yml выглядит слегка эзотерическим
из-за явно полюбившегося разработчикам стиля сочетать императивные инструкции
в декларативном языке, однако всё ещё читаемо, и в своей дефолтной форме
выглядит разумным: выставить входные файлы для filebeat списком в
переменную paths из переменной paths (sic!). В гайде есть пример обработки
многострочного сообщения, что мне, например, совершенно точно пригодится для
того чтобы что-то сделать с ASCII-таблицами ("multiline stitching", и
пригодилось -- см. конец заметки).
А вот что привлекает жадное внимание: ingest/pipeline.json. По
какой-то причине вместо YAML нас заставляют писать на JSON (а, да, RESTFUL),
но и ладно, главное мы наконец-то добрались до Grok-паттернов: они находятся в
процессоре "Grok" списка "processors". Я подготовил выражение для
того чтобы интерпретировать некоторые однострочные сообщения из логов CORAL
в несколько итераций. Уже с первой не обошёлся без дополнительных паттернов
(по существу, алиасы для подвыражений в синтаксисе регулярок Grok):
%{CODE_LOCATION:codeLoc}( ?(==>|-)? %{CORAL_LOGLVL:level})?:? ?%{GREEDYDATA:message}
где паттерны:
CODE_LOCATION (%{WORD:class}::|main)(%{WORD:function}(\(\))?)?
CORAL_LOGLVL (DEBUG|INFO|WARNING|ERROR|FATAL)
Это был мой первый опыт с Grok, так что всё весьма приблизительно, и, может
быть, избыточно. Данный в гайде пример не алиасит паттерны, так что пришлось
поискать другой (см. module/apache2/error/ingest/pipeline.json, ну
или обратите внимание на вот этот параграф
официальной документации).
Уже видно, что пайплайны filebeat позволяют в декларативном виде выражать достаточно сложную пост-обработку логов (полный список доступных процессоров задокументирован в "Ingest node / Processors". Добавив ещё парочку паттернов попроще, ограничимся такой модификацией процессора:
{
"grok": {
"field": "message",
"patterns":[
"Event: %{NUMBER:coral.log.readEventNo} \\(%{NUMBER:coral.log.accountedEventNo}\\)",
"%{CODE_LOCATION:coral.log.codeLoc}: %{MAPS_READ_FAIL:coral.log.message}",
"%{CODE_LOCATION:coral.log.codeLoc} ?(==>|-)? (%{CORAL_LOGLVL:coral.loc.level})?:? ?%{GREEDYDATA:coral.log.message}"
],
"pattern_definitions" : {
"CODE_LOCATION" : "(%{WORD:coral.log.class}::|main)(%{WORD:coral.log.function}(\\(\\))?)?",
"CORAL_LOGLVL" : "DEBUG|INFO|WARNING|ERROR|FATAL",
"MAPS_READ_FAIL" : "Failed to load the map \"%{WORD:coral.log.mapFailure.ChipID}\" from the file %{UNIXPATH:coral.log.mapFailure.Path}"
},
"ignore_missing": true
}
}
Здесь я спекулирую на заметном факте, что многие сообщения пишут префиксом
имя метода класса C++. Внутри кода это сделано не всегда единообразно --
теряются скобки у методов и функций, иногда попадается одно лишь имя класса,
иногда -- одно лишь имя функции, однако это, в принципе, достаточно важная
информация для сортировки сообщений по типу и степени рлевантности, что, в
общем, и есть моя конечная цель. Скользкий момент: парсер регулярок Grok имеют
какие-то проблемы с экранированием символов обычных скобок одним
слэшем (\(\)), им нужен двойной (\\(\\)).
Конечно, штатный референс ELK -- ценный источник по параметризации Grok.
После того как наш pipeline прошёл обкатку на отдельных сообщениях, в пору бы
запустить filebeat на каком-нибудь большом файле, чтобы посмотреть общую
картину. На видео видно, что в директории filebeat/scripts/tester должен быть
скрипт для такой симуляции (интернет находит и релевантный ответ
Noémi Ványi):
scripts/tester$ ./execute_pipeline \
--pipeline ../../module/coral/log/ingest/pipeline.json \
--logfile ../some/where/log.log \
--verbose --simulate.verbose
однако в репозитории я такого скрипта не нашёл. Что ж, видимо придётся тестировать на живом ELK.
Running Filebeat
ELK в Docker удобен среди прочего и тем, что его можно довольно быстро
сбрасывать к исходному состоянию, так что испортив поначалу индекс, всегда
сравнительно легко его восстановить. Для употребления такого ковбойского
подхода воспользуемся локальным filebeat:
$ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.0-linux-x86_64.tar.gz
$ tar xvzf filebeat-6.5.0-linux-x86_64.tar.gz
$ cd filebeat-6.5.0-linux-x86_64
$ cp -r ../some/where/beats/module/coral ./module
$ touch modules.d/coral.yml
$ chmod go-w modules.d/coral.yml
Здесь последней командой я создаю пустой конфигурационный файл для своего рукодельного модуля. Не знаю, насколько это сейчас важно, но у взрослых так...
$ ./filebeat --modules coral -e -c ./filebeat.yml
После непродолжительного "сбора урожая" (сохраним богатую идиоматику ELK через
кальку слова "harvesting", гг), в Kibana появился индекс и какие-то там
сообщения действительно пришли в базу. Правда, помимо coral туда просочилось
(видимо из ванильного конфига) и ещё шесть сотен "посторонних" полей (apache,
nginx, Kafka, etc).
Примечание: это произошло из-за того что я не сгенерировал поля... Вы можете посмотреть вторую часть этой истории для истории чуть более вдумчивых упражнений.
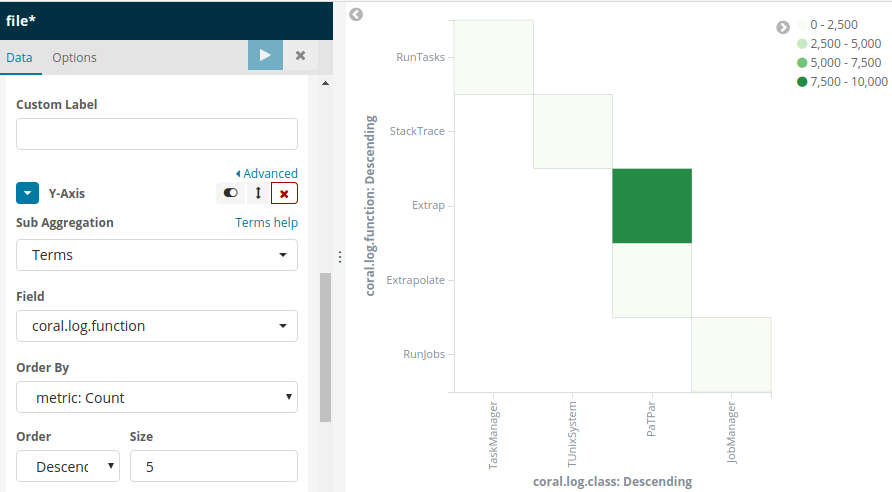
Понятия не имею пока, как конструировать репрезентативные плоты в Kibana, но опыт следования общим соображениям можно посчитать удачным.
Многострочные сообщения
Вдоволь (на самом деле нет) побаловавшись с Kibana, я обнаружил, что некоторые дополнительные опции CORAL позволяют сделать логи структурированными: появляются поля timestamp'а используются информация о месте сообщения в коде. Правда, при этом их формат становится многострочным:
Severity level: INFO
Date: Sun, 18/Nov/2018 01:07:29.021276 (GMT)
File/Facility: CsGEMDetector.cc
Line/Code: 128
Message:
`GM01U1__: Strip amplitude >= 3.000 sigma, Cluster amplitude >= 5.000 sigma'
Severity level: WARNING
Date: Sun, 18/Nov/2018 01:07:27.763419 (GMT)
File/Facility: CsDriftChamberDetector.cc
Line/Code: 140
Message:
`DC00U1__: DeadTime = 60.000000'
Severity level: INFO
Date: Sun, 18/Nov/2018 01:07:29.022610 (GMT)
File/Facility: CsGEMDetector.cc
Line/Code: 162
Message:
`GM01U1__: Polygon for amplitude ratio cut
(0.200,0.060)
(1.100,0.060)
(1.100,1.000)
(0.200,1.000)
'
Severity level: INFO
Date: Sun, 18/Nov/2018 01:07:29.024909 (GMT)
File/Facility: CsGEMDetector.cc
Line/Code: 185
Message:
`GM01U1__: 0.000 <= Multiplicity <= 1000.000'
filebeat вполне
умеет поддерживать
такое, правда сами по себе отладочные средства вроде онлайн-дебаггеров и Kibana
Console уже не позволяют быстро обкатать механизм разделения сообщений. По
сниппетам в приведённой ссылке, однако видно, что они, скорее, перегружают уже
определённую в filebeat-модулях
конфигурацию.
Сама она может быть непосредственно сообщена парсеру в нашем случае в
module/coral/log/config/log.yml:
1 2 3 4 5 6 7 8 9 10 11 | type: log
paths:
{{ range $i, $path := .paths }}
- {{$path}}
{{ end }}
exclude_files: [".gz$"]
multiline:
pattern: "^ Severity level:"
negate: true
match: after
flush_pattern: "^'$"
|
На первый взгляд можно было бы использовать в качестве основной строки события
ту, в которой тело сообщения аключено в кавычки (`'). В этом случае, хватило бы
указать паттерн вроде ^'.+'$ и negate:true, match: before, однако в этом
случае многострочные тела сообщений будут разорваны. Другое наблюдение от
которого я оттолкнулся: пробел перед всеми полями заголовка события за
исключением тела, и Severity level вначале каждого заголовка. Кавычки,
однако, полезны чтобы по ошибке не "сожрать" начало случайного сообщения
(шальной printf(), например) -- их введём через flush_pattern.
Разумеется, для разбора таких сообщений нужно теперь модифицировать pipeline,
попутно встроив туда парсер timestamp'а, который мне пришлось писать руками
(см. Joda patterns),
поскольку лог использует вариацию RFC 1123, но процессор date filebeat не
поддерживает её из коробки:
POST _ingest/pipeline/_simulate
{
"pipeline": {
"description" : "parse multiple patterns",
"processors": [
{
"grok": {
"field": "message",
"patterns":[
"^ Severity level: %{WORD:coral.log.lvl}[\r\n ]+ Date:[\r\n ]+ %{CORAL_DATE:coral.log.msgTime}[\r\n ]+ File/Facility: +%{GREEDYDATA:coral.log.src.filePath}[\r\n ]+ Line/Code: *%{NUMBER:coral.log.src.nLine}[\r\n ]+ Message:[\r\n]*`(?m)%{GREEDYDATA:coral.log.msg}'",
"^Event: %{NUMBER:coral.log.readEventNo} \\(%{NUMBER:coral.log.accountedEventNo}\\)$",
"^%{CODE_LOCATION:coral.log.codeLoc}: %{MAPS_READ_FAIL:coral.log.message}$",
"^%{CODE_LOCATION:coral.log.codeLoc} ?(==>|-)? (%{CORAL_LOGLVL:coral.loc.level})?:? ?%{GREEDYDATA:coral.log.message}$"
],
"pattern_definitions" : {
"CORAL_DATE" : "%{DAY:coral.log.msgCmp.weekDay}, %{MONTHDAY:coral.log.msgCmp.dayDate}/%{MONTH:coral.log.msgCmp.monthName}/%{YEAR:coral.log.msgCmp.year} %{TIME:coral.log.msgCmp.dayTime} \\(GMT\\)",
"CORAL_MESSAGE" : "[.\n\r]+",
"CODE_LOCATION" : "(%{WORD:coral.log.class}::|main)(%{WORD:coral.log.function}(\\(\\))?)?",
"CORAL_LOGLVL" : "DEBUG|INFO|WARNING|ERROR|FATAL",
"MAPS_READ_FAIL" : "Failed to load the map \"%{WORD:coral.log.mapFailure.ChipID}\" from the file %{UNIXPATH:coral.log.mapFailure.Path}"
},
"ignore_missing": true
}
},
{
"rename": {
"field": "_ingest.timestamp",
"target_field": "read_timestamp",
"ignore_missing" : true
}
},
{
"date": {
"field": "coral.log.msgTime",
"target_field": "_ingest.timestamp",
"formats": ["UNIX", "EEE, dd/MMM/yyyy hh:mm:ss.SSSSSS (zzz)"]
}
},
{
"remove": {
"field" : ["coral.log.msgCmp", "coral.log.msgTime"],
"ignore_missing" : true
}
}
],
"on_failure" : [{
"set" : {
"field" : "error.message",
"value" : "{{ _ingest.on_failure_message }}"
}
}]
},
"docs":[
{
"_source": {
"message": " Severity level: INFO\n Date: Sun, 18/Nov/2018 01:07:29.022610 (GMT)\n File/Facility: CsGEMDetector.cc\n Line/Code: 162\n Message:\n`GM01U1__: Polygon for amplitude ratio cut\n(0.200,0.060)\n(1.100,0.060)\n(1.100,1.000)\n(0.200,1.000)\n'"
}
}, {
"_source": {
"message": "TSetup::Init() ==> INFO: dead zone in detector DC01V2 will be considered as active"
}
}]
}
Директорию coral/ я поместил уже в репозиторий со своим основным проектом,
бросив симлинк в filebeat/module/coral -> path/to/my/proj/elk-module. Вместе
с конфигом вида
- module: coral
log:
enabled: true
var.paths:
- /path/to/test/logs/*
размещённым в filebeat/modules.d/coral.yml получается beat который уже можно
запускать на "живом" наборе файлов с логами с тем чтобы отлаживать по
результатам видимым в Kibana.
We need to go deeper
На этом этапе стало ясно, что даже для столь гетерогенного лога при помощи ELK можно выуживать чрезвычайно полезную информацию, и я, закатав рукава, решился на создание полноценного модуля, однако дальнейшие изыскания выходят за рамки данной заметки, целью которой была лишь рекогнисцировка.
References
- Brief intro with docker".
- Module devlopment guide".
- Demonstration video of how to develop your own module.
- Online Grok ctr.
- Multiline examples.
- Benefits of introducing Logstash.
Comments

© Copyright 2016, under the auspices of Q‐crypt foundation / под эгидой Q-crypt foundation
Materials are free free for distribution under the terms of CreativeCommons Attribution ShareAlike CC BY SA 4.0. / Материалы свободны к распространению в рамках CC BY SA 4.0